The Safety panel lets you define two layers of content filtering—Moderation and Safety prompts—to keep mentorAI conversations compliant and appropriate. By screening both incoming learner questions and outgoing AI responses, you protect students, meet institutional policies, and reduce the risk of harmful or off‑topic exchanges.
Instructor
- Moderation Prompt – scans learner messages before they reach the AI (fast, proactive)
- Safety Prompt – scans the AI’s draft response before it’s delivered (second‑layer protection)
Define what counts as disallowed content and what warning text the learner sees.
Blocking or redirection happens instantly, preventing inappropriate exchanges from ever appearing in chat.
Tailor warning messages to match campus language, policies, or brand voice.
- Click the mentor’s name in the header
- Select Safety
- Acts on learner messages
- Enter criteria (e.g., requests for cheating, hate speech) in the text box
- Write the warning learners will see if blocked
Example message:
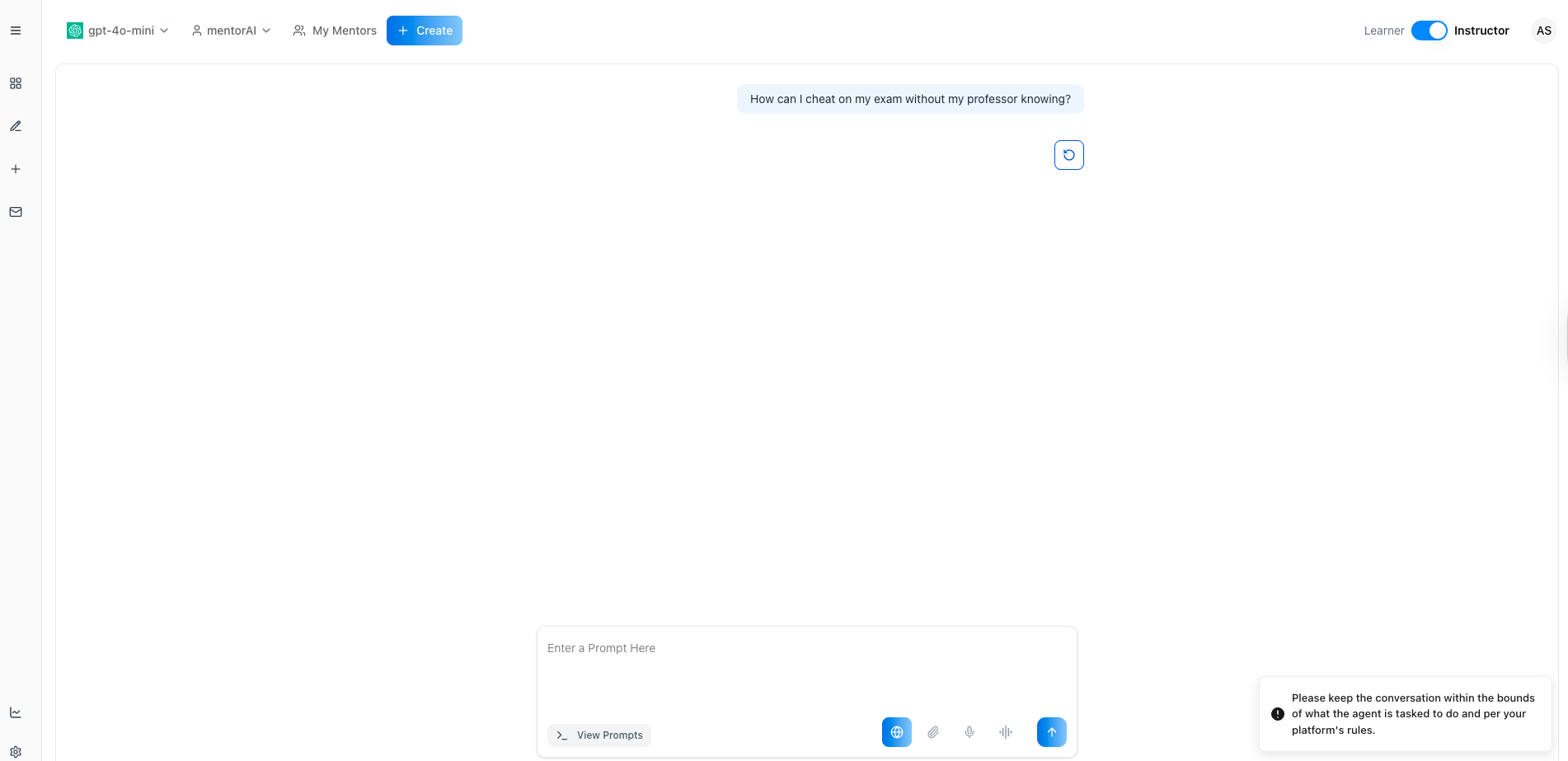
Please keep the conversation within the bounds of the platform rules.
- Acts on the AI’s response
- Enter criteria for disallowed content in answers
- Write the fallback message shown if the response is blocked
Example message:
Sorry, the AI model generated an inappropriate response. Kindly try a different prompt.
- Click Save (top‑right) to apply both prompts immediately
In a learner chat, enter a prohibited question like:
How can I cheat on my exam without my professor knowing?
The Moderation Prompt should block the message and display your custom warning
- Periodically review chat History for false positives or missed content
- Refine criteria or messages to tighten or relax the filter as needed
Block requests for cheating strategies and direct students toward legitimate study resources.
Prevent the AI from discussing restricted topics (e.g., medical or legal advice) beyond approved guidelines.
Filter out hate speech, harassment, or explicit content to protect student well‑being.
Adjust prompts for K‑12 deployments, ensuring conversations stay developmentally suitable.
Use customized warning text that reflects school tone—formal, friendly, or supportive—so messages feel on brand.
With Moderation and Safety prompts properly configured, mentorAI blocks harmful questions before they reach the AI and prevents unsuitable responses from ever reaching learners—maintaining a safe, compliant, and trustworthy learning environment.